innodb数据存储格式
- InnoDB数据存储格式
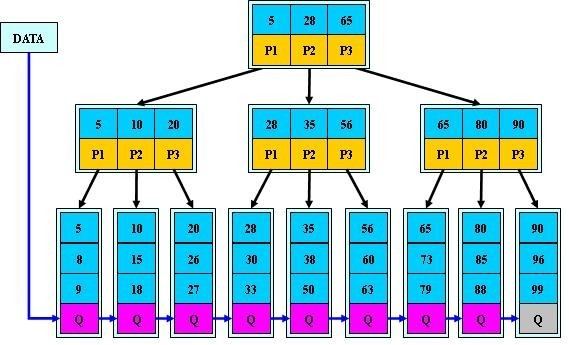
innodb存储的数据结构是B+树,B+树是应文件系统所需而生的一种B树变形树,特点是所有的数据均存储在叶子节点中,非叶子节点相当于索引,这样有利于在搜索数据时每次读取多个节点,减少磁盘io。
B+树
关于B树、B+树更多的学习可以参看从B树、B+树、B*树谈到R 树。
innodb的数据存储跟索引离不开关系,因为实际上来讲,innodb的数据就是存储在聚簇索引中的,如果建表存在主键或者唯一键,innodb会选取为聚簇索引,并且数据的存储就会按照主键或唯一键来存储,此时便是一个聚簇表;如果并不存在类似的键,innodb会自建一个内置的无序列来作为聚簇索引,此时数据的存储便是无序的,是一个堆表。
聚集索引。表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
非聚集索引。表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
一个建表实例:
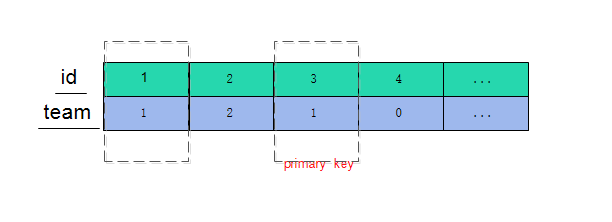
1 2 3 4 5 6 7 | CREATE TABLE `tab_no_index` ( -> `id` int(11) NOT NULL DEFAULT '0', -> `team` int(11) DEFAULT '0', -> PRIMARY KEY (`id`), -> KEY `team` (`team`) -> ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ; insert lock_test values(1,1),(2,2),(3,1),(4,0),(5,5),(10,10),(19,20); |
主键索引实际上就是存储数据的聚簇索引,也可以这么说,聚簇索引就是一张表。
主键
二级索引B+树子节点存储的实际上是主键的key值,因此实际上如果查询不是覆盖索引,那么走二级索引时还需要通过二级索引查到的主键值到主键索引中查多一次,至少需要多一次磁盘io,可见效率的差别。

二级索引
- 覆盖索引
覆盖索引的概念是对于二级索引而言的,也就是说sql查询时查询条件全在二级索引中并且可以从二级索引中获取到所需要的查询数据,不需要回表查询,此时io只会建立在索引的搜索上,比方说查询索引列或者主键值。当sql覆盖索引时,通过explain计划任务可以看到Extra的值为use index,如果是需要回表查询的,则会是use where。
mysql优化器分割where子句【何登成】 Fiddler中显示IP的设置方法